
システムプログラミング入門としてのRust製スレッドスケジューラー
#tech#Rust2025-12-25
Rustは特にシステムプログラミングに向いているとされています.しかしながら実際にRustでシステムプログラミングをしてみたい!と思う方でも,取り組む題材の選定に困った方は多いのではないでしょうか.例えば自作OSはその花形だと思いますが,敷居が高く思えてなかなか手が出ない方もおられると思います.
本記事ではそれに対して,簡易なグリーンスレッドスケジューラーを作成するのが適しているのではないか,という主張をし,実際に作成します.本主張の主な根拠は次のとおりです:
- 高級プログラミング言語(Rust)からアセンブリによる低レイヤー操作まで広く触れられる
- 設計によってはシステムコール,シグナル,割り込み,スタック,メモリオーダリング等の周辺知識にも多く触れることができる
- スケジューラーの機能面での拡張の余地が大きい
- goroutineやtokioのような既存のグリーンスレッドランタイムが本質的にどの様なことをしているのか[1]に触れることができる
実際に作成したスレッドスケジューラーは次のリポジトリで公開しています.分量の都合上実装の全てについて解説は行いませんので適宜こちらをサンプル実装として参照してください.本サンプル実装ではx86_64とAArch64のLinuxやmacOS等のUNIXライクなOSで動作するようになっています.
この記事はRust Advent Calendar 2025の25日目の記事であり,同時に2025年11月初頭に開催された,筆者の所属先である筑波大学の学園祭の企画で頒布した技術同人誌に寄稿した内容をブログ用に改変したものです.本記事では実装の細部の解説や本筋でない機能の説明等はその多くを割愛している[2]ので,より詳細を知りたい方や,他の記事(寄稿者達の専門を活かした様々な内容の記事があります!)に興味がある方は同人誌の方をぜひお読みいただきたいです.次のリンクで一般販売をしています:
また,本記事で断りなく"スレッド"という語を用いる場合,これはグリーンスレッドのことを指します.
まずスレッドスケジューリングの基本的な概念について説明します.スレッドスケジューリングは大きく分けて協調的スケジューリングとpreemptiveスケジューリングに大別されます.
協調的スケジューリングでは,各スレッドが自発的に自らのスレッドの実行の終了をスケジューラーに通知することによりスレッドが終了します.これはあるスレッドがいつまでも終了しなければ他のスレッドも含めた全体の進行が止まってしまうことを意味します.
他方,preemptiveスケジューリングでは,スケジューラーが一定の基準,例えば長時間実行を続けているスレッドなどに対して途中で実行を打ち切り,代わりに他のスレッドを実行するようにします.しかしそれでは実行途中のスレッドが中断される可能性があるため,このような場合にはコンテキストスイッチと呼ばれる機構を用いて,実行途中のスレッドの状態を安全に保存した上で,実行するスレッドを切り替える必要があります.この点で,preemptiveなスケジューリングにおいては若干のオーバーヘッドが発生しますが,特定のタスクによって全体が停止することはないというのがメリットといえます.
すなわち両スケジューリングの動きの例を示すと次図のようになります.ここでは比較的実行に時間がかからないスレッドTask 3と時間がかかるスレッドTask 2,これらの中間くらいの時間がかかるTask 1を考えて,これらがTask 1,Task 2,Task 3の順に実行依頼がスケジューラーに到着した場合を考えます.
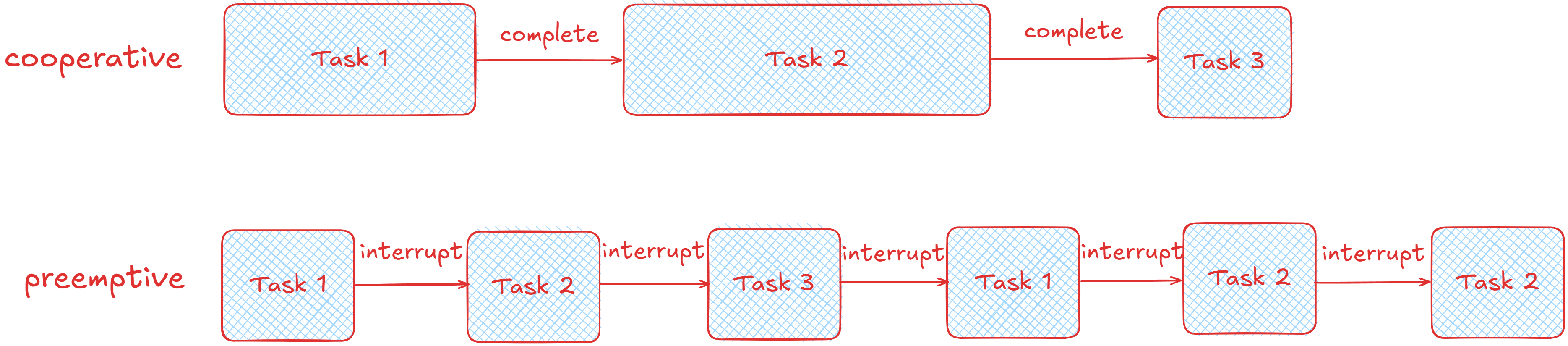
2つのスケジューリング方式の比較
協調的スケジューリングの場合は各スレッドの実行完了を待ってから次のスレッドに実行が遷移するので,単体では比較的実行に時間がかからないTask 3も,実行が完了するのは他のスレッドの完了待ちにより遅くなってしまいます.
一方でpreemptiveスケジューリングの場合はスレッドが一定の時間実行されたら途中で打ち切って他のスレッドに実行を移譲するのでTask 3の実行が比較的早く終了する様子が分かります.Task 1やTask 2の残りの作業はTask 3が完了後に再び再開されて実行されます.
最初に慣れの意味も込めて協調的スケジューラーを作ります.これは比較的簡単に実装可能です.
まずはユーザースレッド(今回はクロージャーとして表現します)とスケジューラーをRust上で表現します.それぞれTask型とCooperativeScheduler構造体として,次のようにします:
type Task = Box<dyn FnOnce() + Send + 'static>;
pub struct CooperativeScheduler {
queue: std::sync::Arc<std::sync::Mutex<std::collections::VecDeque<crate::types::Task>>>,
}
ここでTask型はFnOnceを持っているのでクロージャーであることを,Sendを持っているのでスレッドセーフであることを示します.タスクキューをArcとMutexで包んでいるのは将来マルチスレッド対応したくなったときのことを見据えています(本記事ではそこまで実装していませんが比較的単純に達成可能ですので余力がある場合はぜひ).
これを用いて実際にスレッドを追加するメソッドadd_taskと,スケジューラーが持っているスレッドを順に実行するrunメソッドなどを作成します(エラーはカスタムエラー型を適当に作成しています):
impl CooperativeScheduler {
pub fn new() -> Self {
CooperativeScheduler {
queue: std::sync::Arc::new(std::sync::Mutex::new(std::collections::VecDeque::new())),
}
}
pub fn add_task(&self, task: crate::types::Task) -> crate::error::Result<()> {
let mut q = self
.queue
.lock()
.map_err(|_| crate::error::Error::LockFailed)?;
q.push_back(task); // キューにタスクを追加
Ok(())
}
pub fn run(&self) -> crate::error::Result<()> {
// キューの中身が空になるまで各タスクを実行する
while let Some(task) = {
let mut q = self
.queue
.lock()
.map_err(|_| crate::error::Error::LockFailed)?;
q.pop_front()
} {
// キューをpopした結果が`Some`ならタスクなので中身を実行
task();
}
Ok(())
}
}
これで協調的スケジューラーが実装できました.次のサンプルコードのようにして実際に使うことができます.
協調的スケジューラーを使うサンプルコード
ここでは初期値0のcounterという変数を用意して,forの中でこのcounterをインクリメントするスレッドを5個作成します.
これらをスケジューラーにエンキューしてrunメソッドで実行するので最終的にcounterの値が5になることを確認できます.
fn foo() {
let scheduler = crate::cooperative::CooperativeScheduler::new();
let counter = std::sync::Arc::new(std::sync::Mutex::new(0));
for _ in 0..5 {
let counter_clone = std::sync::Arc::clone(&counter);
scheduler
.add_task(std::boxed::Box::new(move || {
let mut num = counter_clone.lock().unwrap();
*num += 1;
}))
.unwrap();
}
scheduler.run().unwrap();
assert_eq!(*counter.lock().unwrap(), 5);
}
次にpreemptiveスケジューラーを作ります.ここからが本題です.
今回作成するスケジューラーは次のような機能を持ちます:
- 各スレッドは連続した実行時間が指定された時間(スケジューラーインスタンスを作成する際に設定可能)を超過するとスケジューラーによって実行が中断される
- 中断されたスレッドは,そのタスクが完了していないならキューの末尾に回される(ラウンドロビン)
- 実行の中断/再開はアセンブリを経由したコンテキストスイッチによって行われる
まずは初期準備として,スレッドの状態をenumで管理できるようにします.今回はスレッドは次の3状態のいずれかを取ります:
#[derive(Debug)]
pub enum ThreadState {
Ready,
Running,
Terminated,
}
これらは次のようなライフサイクルを持ちます:
Ready -schedule()-> Running
^ |
| |
└---schedule()------┘
|
v
Terminated
スレッドが作成されてReady状態になったら,スケジューラーがそのスレッドをスケジューリングします.実際にスケジューリングされたスレッドが実行されるときにはRunningになります.スレッドは一定時間実行されたらスケジューラーによって実行が中断されることで再びReady状態に戻ります.最終的にスレッドの実行が完了するとTerminated状態となります.
実際にスケジューラーを使う側がスケジューラーのインスタンスを作成する際には次のようにパラメーターをメソッドチェインで指定出来て,最後にbuildメソッドを呼び出すことでスケジューラーの設定を確定するようなビルダーパターンで指定できると便利です.
let scheduler = lachesis::Lachesis::builder()
.stack_size(4 * 1024 * 1024) // スタックサイズを4MBに設定
.preemption_interval(10) // preemptionの割り込みチェックの間隔を指定
.build(); // スケジューラーのオプションを確定させる
これを実現するためにスケジューラーの構造体(リポジトリの名前をlachesisにしているのでLachesisとします)を次のように定義します:
pub struct Lachesis {
config: crate::types::SchedulerConfig,
initialized: std::sync::Arc<std::sync::atomic::AtomicBool>,
}
ここでinitializedはスケジューラーが正常に初期化済みであるかどうかを示すフラグで,configは次のようなメンバーを持つ,パラメーター設定の構造体です:
#[derive(Debug, Clone)]
pub struct SchedulerConfig {
pub default_stack_size: usize,
pub preemption_interval_ms: u64,
}
これらのメンバーはそれぞれスタックサイズ,割り込みチェックの間隔(ミリ秒)を表します.各パラメーター設定とスケジューラーインスタンスのパラメーターを確定させるbuildメソッドを次のように書けばビルダーパターンでスケジューラーを作成できるようになります.
ビルダーパターンのためのメソッド群
pub struct ConfigBuilder {
config: crate::types::SchedulerConfig,
}
impl ConfigBuilder {
pub fn new() -> Self {
ConfigBuilder {
config: crate::types::SchedulerConfig::default(),
}
}
pub fn stack_size(mut self, size: usize) -> Self {
self.config.default_stack_size = size;
self
}
pub fn preemption_interval(mut self, ms: u64) -> Self {
self.config.preemption_interval_ms = ms;
self
}
pub fn build(self) -> Lachesis {
Lachesis {
config: self.config,
initialized: std::sync::Arc::new(std::sync::atomic::AtomicBool::new(false)),
}
}
}
次にスレッドを作成(spawn)できるようにします.スレッドは協調的スケジューリングの場合と同様クロージャーで表現するだけでなく,関数を(関数ポインターとして)渡して実行できるとさらに便利なのでどちらの形式でも実行できる形式を考えます.
まず各スレッドには一意なIDを付けて管理したいので,次のような乱数を用いてスレッドIDを新規作成する関数を作っておきます:
pub fn get_id() -> u64 {
loop {
let rnd = rand::random::<u64>();
unsafe {
let id_ptr = &raw mut ID;
if !(**id_ptr).contains(&rnd) {
(**id_ptr).insert(rnd);
return rnd;
}
}
}
}
ここまでの下準備を元に,spawnを行うspawnメソッドでは以下のようなことを行います.
- スレッドIDを作成する
Context構造体のインスタンスを作成する- 実行可能なタスクを
executableフィールドに保存する(クロージャーの場合) - スレッドの状態を
Readyに設定する - スケジューラーにスレッドを認識させる
実装は次のとおりです:
pub fn spawn<F>(func: F, stack_size: usize) -> u64
where
F: FnOnce() + Send + 'static,
{
unsafe {
let id = get_id();
let mut ctx = Box::new(crate::context::Context::new(None, stack_size, id));
ctx.executable = Some(Box::new(func));
ctx.state = crate::ThreadState::Ready;
let contexts_ptr = &raw mut CONTEXTS;
(*contexts_ptr).push_back(ctx);
schedule();
id
}
}
このようにspawnメソッドはジェネリックな型パラメーターFを取り,FnOnce() + Send + 'staticトレイト境界を満たす任意の関数やクロージャーを受け入れることができます.spawn関数では常にContext::new()のentry引数にNoneを渡し,executableフィールドにBox::new(func)で包んだ関数やクロージャーを保存します.
一方で後述するspawn_from_main関数では,内部的に固定の関数ポインターを使用するため,entryフィールドにSome(func)を渡し,executableはNoneとします.この使い分けは,spawnがユーザーから呼び出される汎用的なAPIであるのに対し,spawn_from_mainはランタイム初期化時に内部的に使用される特殊なケースであるためです.
上記のspawnメソッドはジェネリックな型パラメーターFを受け取り,関数ポインターとクロージャーの両方を扱うことができます.この仕組みにより,次のように関数ポインターとクロージャーの両方を同じspawn関数で扱えます:
// 関数ポインター
fn worker_thread() {
println!("Worker thread");
}
lachesis::spawn(worker_thread, 2 * 1024 * 1024);
// クロージャー
let thread_name = "Closure Worker";
let iteration_count = 8;
lachesis::spawn(move || {
println!("{} starting (iterations: {})", thread_name, iteration_count);
for i in 0..iteration_count {
println!("{}: {}", thread_name, i);
}
}, 2 * 1024 * 1024);
この機能は次のようなトレイトを定義することで実現します:
pub trait Executable: Send + 'static {
fn execute(self: Box<Self>);
}
impl<F> Executable for F
where
F: FnOnce() + Send + 'static,
{
fn execute(self: Box<Self>) {
self();
}
}
Executableトレイトは実行可能なタスクを表すトレイトで,FnOnce() + Send + 'staticを満たす任意の型に対して自動的に実装されます.これにより関数ポインターとクロージャーの両方をBox<dyn Executable>として扱うことができます.
Context構造体にはOption<Box<dyn Executable>>型のexecutableメンバーを持たせます.spawn関数から作成されるスレッドでは,関数ポインターであってもクロージャーであってもexecutableメンバーに保存されます.これはExecutableトレイトがFnOnce() + Send + 'staticを満たす任意の型に対して実装されているためです.entryメンバーはspawn_from_main関数など,ランタイム内部で固定の関数ポインターを直接指定する場合にのみ使用されます.この実装により,型システム上で関数ポインターとクロージャーを統一的に扱えるようになります.
スレッドが実際に実行を開始する際,直接ユーザー関数を呼び出すのではなく,専用のentry_point関数を経由します.この関数は次の役割を持っています:
- ユーザー関数の実行: 実際のユーザー関数を実行
- クリーンアップ: 関数の実行終了後にスレッドの状態を
Terminatedに設定 - リソース解放: 終了したスレッドIDをIDセットから削除
- スタックの保存: 終了したスレッドのスタック領域を保存(将来の再利用のため)
- 次のスレッドへの切り替え: 他のスレッドがあれば切り替え,なければメインスレッドに戻る
実装は次のようにしています:
entry_point関数の実装
pub extern "C" fn entry_point() -> ! {
unsafe {
let contexts_ptr = &raw mut CONTEXTS;
let ctx = (*contexts_ptr).front_mut().unwrap();
if let Some(executable) = ctx.executable.take() {
executable.execute();
} else if let Some(entry) = ctx.entry {
entry();
}
// Thread cleanup
let contexts_ptr = &raw mut CONTEXTS;
let mut ctx = (*contexts_ptr).pop_front().unwrap();
ctx.state = crate::ThreadState::Terminated;
// Remove thread ID
let id_ptr = &raw const ID;
if !(*id_ptr).is_null() {
let id_ptr = &raw mut ID;
(**id_ptr).remove(&ctx.id);
}
let unused_ptr = &raw mut UNUSED_STACK;
*unused_ptr = (ctx.stack, ctx.stack_layout);
match (*contexts_ptr).front_mut() {
Some(c) => {
c.state = crate::ThreadState::Running;
let current_id_ptr = &raw mut CURRENT_THREAD_ID;
*current_id_ptr = c.id;
crate::context::switch_context(c.get_regs());
}
None => {
// All threads finished - return to main
crate::timer::disable_preemption();
let ctx_main_ptr = &raw const CTX_MAIN;
if let Some(c) = &*ctx_main_ptr {
crate::context::switch_context(&**c as *const crate::context::Registers);
}
}
};
}
unreachable!();
}
entry_pointの冒頭でexecutableフィールドの有無を確認することにより,executableが設定されている場合(クロージャーの場合)はトレイトオブジェクトのexecute()メソッドを呼び出し,設定されていない場合はentryフィールドの関数ポインターが指す関数をそのまま実行します:
if let Some(executable) = ctx.executable.take() {
executable.execute();
} else if let Some(entry) = ctx.entry {
entry();
}
スレッドが終了する際には,そのスタック領域を即座に解放するのではなく,グローバル変数に保存することでスタックの再利用を可能にしています.これによりスタックの確保という比較的高コストな操作を削減し,パフォーマンスを向上させることができると考えられます[3].
ここまででスレッドの作成(spawn)とエントリーポイント(entry_point)を実装しましたが,スケジューラー全体を起動するための仕組みが必要です.ユーザーがスケジューラーを使用する際の典型的なコードは次のようになります:
fn main() {
let scheduler = lachesis::Lachesis::builder()
.stack_size(4 * 1024 * 1024)
.preemption_interval(10)
.build();
scheduler.run(|| {
// ここにメインのグリーンスレッドの処理
lachesis::spawn(worker_thread, 2 * 1024 * 1024);
}).unwrap();
}
このような使い方を実現するために,次の3つの要素を実装します:
Lachesis::run()メソッド
Lachesis構造体のrun()メソッドは,ユーザーから渡されたクロージャーをメインのグリーンスレッドとして実行します.これはまずスケジューラーが二重に初期化されていないかをinitializedフラグでチェックし,その後,設定されたスタックサイズとプリエンプション間隔をexecute_main()関数に渡してランタイムを起動します.
execute_main()関数とスレッドローカル変数
execute_main関数は,ジェネリックなクロージャーを受け取り,それを関数ポインターとしてspawn_from_main関数に渡すための橋渡しをします.しかしながら,ジェネリックなクロージャーは直接fn()型の関数ポインターに変換することはできません.この問題を解決するために,thread_local!マクロを用いてクロージャーを一時保存します:
thread_local! {
static CURRENT_FUNCTION: std::cell::RefCell<
Option<Box<dyn crate::types::Executable>>
> = std::cell::RefCell::new(None);
}
thread_local!マクロはスレッドごとに独立した静的変数を定義できます.execute_main関数では次の手順を踏みます:
- ユーザーから渡されたクロージャーを
CURRENT_FUNCTIONというスレッドローカル変数に保存 main_entryという固定の関数ポインターを定義(この中でスレッドローカル変数からクロージャーを取り出して実行)spawn_from_mainにmain_entryを関数ポインターとして渡す
これにより,各OSスレッドごとに独立したクロージャーを保存でき,main_entry関数内でそれを取り出して実行できます.
spawn_from_main()関数
最後に,spawn_from_main()関数がメインスレッドのコンテキストを作成し,グリーンスレッドのランタイムを起動します.この関数は次のようなことを行います:
- メインスレッド(OSスレッド)のコンテキストを
CTX_MAINに保存 set_context()で現在の実行状態を保存(戻ってくるための位置を記録)- 最初のグリーンスレッドを作成して
switch_context()で切り替え - 全てのグリーンスレッドが終了すると,保存されたメインスレッドのコンテキストに戻る
- 終了時にリソースをクリーンアップ
実行フロー全体
以上の3つのコンポーネントにより,次のような実行フローが実現されます:
- ユーザーが
scheduler.run(closure)を呼ぶ Lachesis::runがexecute_main(closure, ...)を呼ぶexecute_main()がクロージャーをスレッドローカル変数に保存し,spawn_from_main()を呼ぶspawn_from_main()がメインスレッドのコンテキストを保存し,グリーンスレッドに切り替えmain_entry()が実行され,スレッドローカル変数からクロージャーを取り出して実行- クロージャー内で
spawn()により他のグリーンスレッドが作成される - 全てのグリーンスレッドが終了すると,メインスレッドに戻る
Lachesis::run()が終了し,制御がユーザーコードに戻る
コンテキストスイッチの詳細に入る前に,スケジューリングの中核となるschedule()関数について説明します.この関数はspawnやcheck_preemptionから呼び出され,実際にスレッドの切り替えを行います:
pub fn schedule() {
unsafe {
let contexts_ptr = &raw mut CONTEXTS;
if (*contexts_ptr).len() <= 1 {
return; // スレッドが1つ以下なら切り替え不要
}
// 現在のスレッドをキューの末尾に移動(ラウンドロビン)
let mut ctx = (*contexts_ptr).pop_front().unwrap();
ctx.state = crate::ThreadState::Ready;
let regs = ctx.get_regs_mut();
(*contexts_ptr).push_back(ctx);
// set_contextで現在の状態を保存し,0が返ったら次のスレッドに切り替え
if crate::context::set_context(regs) == 0
&& let Some(next) = (*contexts_ptr).front_mut()
{
next.state = crate::ThreadState::Running;
let current_id_ptr = &raw mut CURRENT_THREAD_ID;
*current_id_ptr = next.id;
crate::context::switch_context(next.get_regs());
}
}
}
この関数の動作を順に説明します:
- まずスレッドが1つ以下であれば切り替える必要がないので早期リターンします
- キューの先頭から現在実行中のスレッドを取り出し,状態を
Readyに変更してキューの末尾に追加します(ラウンドロビン方式) set_contextで現在のレジスタ状態を保存します.この関数は最初の呼び出し時に0を返し,switch_context経由で戻ってきた場合は1を返します(setjmp/longjmpに似たパターン)- 戻り値が0の場合,キューの先頭にある次のスレッドの状態を
Runningに変更し,switch_contextでそのスレッドに切り替えます
実行するスレッドを切り替えるために,コンテキストスイッチを実装します.これは現在実行中のスレッドのレジスタの状態をどこかに退避して,次に実行するスレッドのレジスタの状態を実際のCPUレジスタに復帰させる操作が必要です.これはスケジューラー側で管理している各スレッドの状態に,レジスタの情報を持たせることで達成できます.例えばx86_64であれば(以降x86_64を例として説明します)次のように,コンテキストスイッチ時に退避/復帰させるレジスタの値を格納する構造体を用意して:
#[cfg(target_arch = "x86_64")]
#[repr(C)]
pub struct Registers {
pub rbx: u64,
pub rbp: u64,
pub r12: u64,
pub r13: u64,
pub r14: u64,
pub r15: u64,
pub rsp: u64,
pub rdx: u64,
}
別途アセンブリを書いてFFIで呼び出します.まずコンテキストをセットするSET_CONTEXTルーチンは次のように書けます:
.text
.align 4
SET_CONTEXT:
pop %rbp
xor %eax, %eax ; 戻り値を0に設定
movq %rbx, (%rdi) ; callee-savedレジスタを保存
movq %rbp, 8(%rdi)
movq %r12, 16(%rdi)
movq %r13, 24(%rdi)
movq %r14, 32(%rdi)
movq %r15, 40(%rdi)
lea 8(%rsp), %rdx ; スタックポインターを保存
movq %rdx, 48(%rdi)
push %rbp
movq (%rsp), %rdx ; 戻りアドレスを保存
movq %rdx, 56(%rdi)
ret
この関数は現在のレジスタ状態を引数で渡されたRegisters構造体に保存し,戻り値として0を返します.
また,スレッドのコンテキストを作成する際には,スタックオーバーフローからの保護のためにガードページを設定します.一般にスタックは次図のように下方向に伸びていきます:
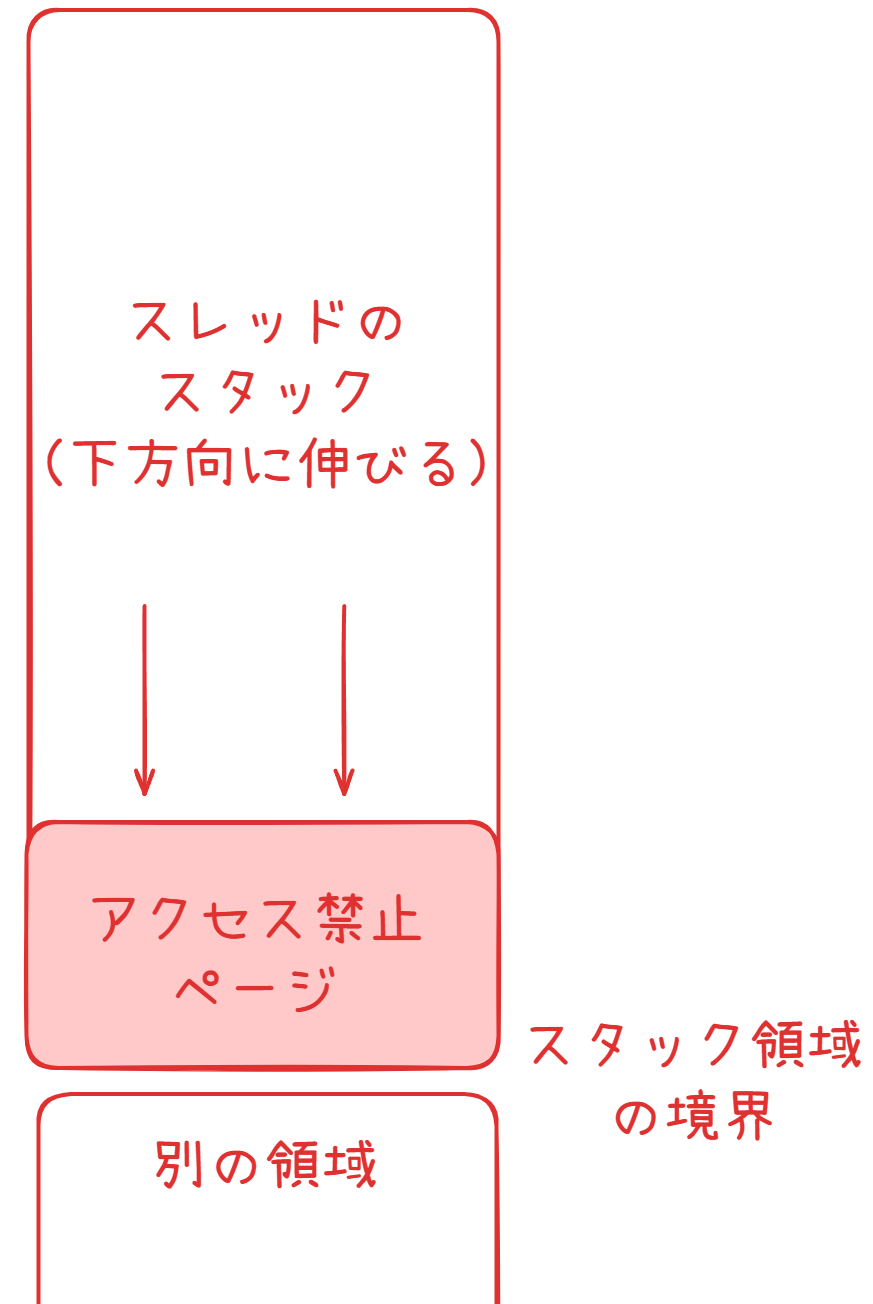
ガードページの仕組み
よって各スレッドが確保するスタック領域の末尾部分1ページを読み書き実行全て禁止(PROT_NONE)にすることで,スタックオーバーフローが発生した際にこの領域が踏まれてsegfaultが発生するようにできます.これでスタックオーバーフローによるメモリ破壊を防ぐことが可能になります:
pub fn new(func: Option<crate::types::Entry>, stack_size: usize, id: u64) -> Self {
let layout = std::alloc::Layout::from_size_align(stack_size, PAGE_SIZE).unwrap();
let stack = unsafe { std::alloc::alloc(layout) };
// ガードページの設定
unsafe {
let non_null_ptr = std::ptr::NonNull::new(stack as *mut std::ffi::c_void).unwrap();
nix::sys::mman::mprotect(
non_null_ptr,
PAGE_SIZE,
nix::sys::mman::ProtFlags::PROT_NONE,
)
.unwrap();
};
// ...
}
次にSWITCH_CONTEXTルーチンを実装します.これは保存されたコンテキストに切り替える関数で,大体SET_CONTEXTの逆っぽいことをやれば良いです:
.text
.align 4
SWITCH_CONTEXT:
xor %eax, %eax
inc %eax ; 戻り値を1に設定
pop %rsi ; 戻りアドレスを退避
movq (%rdi), %rbx ; callee-savedレジスタを復帰
movq 8(%rdi), %rbp
movq 16(%rdi), %r12
movq 24(%rdi), %r13
movq 32(%rdi), %r14
movq 40(%rdi), %r15
movq 48(%rdi), %rdx ; スタックポインターを復帰
movq %rdx, %rsp
addq $0x8, %rsp
push %rbp
push %rsi
movq 56(%rdi), %rdx ; ジャンプ先アドレスを取得
jmpq *%rdx ; そのアドレスにジャンプ
この関数はRegisters構造体から保存されたレジスタ状態を復帰し,保存されていたアドレスにジャンプします.SET_CONTEXTは0を返しますが,SWITCH_CONTEXT経由でSET_CONTEXTの呼び出し元に戻る場合はeaxに1が設定します.これによりschedule()関数内で「最初の呼び出しか,切り替え後の復帰か」を判定できます.
Rustコード側ではbuild.rsで,先ほどのアセンブリファイルをコンパイルしたものをリンク対象に含めるようにして,次のようなシグネチャを宣言しておけばFFIで呼び出せるようになります:
unsafe extern "C" {
pub fn set_context(ctx: *mut Registers) -> u64;
pub fn switch_context(ctx: *const Registers) -> !;
}
preemptiveなスケジューリングを実現するためには,あるスレッドの実行時間があらかじめ設定した時間を超えたら強制的にコンテキストスイッチを行う仕組みが必要です.この機能を実装するにあたっては,OSが提供するシグナル機構とタイマー機構を利用します.
本実装ではSIGALRMという実時間に基づいて発出されるシグナルを利用します.別のOSスレッドで定期的なタイマーを実行しておいて,そのタイマーが発火するたびに自プロセスにSIGALRMシグナルを送信します.
タイマー割り込みは次のような手順で実装します:
- シグナルハンドラーの登録:
SIGALRMシグナルが発出された時に実行される関数を登録する - タイマースレッドの起動: 別スレッドを起動し,指定された間隔ごとに自プロセスに
SIGALRMシグナルを送信する - フラグによる制御: アトミックなフラグを用いてコンテキストスイッチ機構を制御する
nixクレートのSigHandlerを用いるとシグナルハンドラーを簡単に作成できます.SIGALRMシグナルが発出された時に,これをフックして特定の関数を実行するシグナルハンドラーを作成します:
pub fn init_timer(interval_ms: u64) {
unsafe {
let handler =
nix::sys::signal::SigHandler::Handler(preemption_signal_handler);
nix::sys::signal::signal(nix::sys::signal::Signal::SIGALRM, handler).unwrap();
// ...後の処理
}
}
ここでSIGALRMシグナルが発出されたときにpreemption_signal_handler関数を実行するように設定しています.この実装は次のようになります:
extern "C" fn preemption_signal_handler(_: i32) {
crate::types::PREEMPTION_REQUESTED.store(true, std::sync::atomic::Ordering::Relaxed);
}
このハンドラーはPREEMPTION_REQUESTEDというアトミックフラグをtrueに設定するだけのシンプルな処理を行います.ここでRelaxedオーダリングを使用しているのは,シグナルハンドラー内では複雑な同期処理を避けるべきであり,単純なフラグの設定だけを行えば十分だからです.実際のコンテキストスイッチはチェックポイントに到達した時に行われます.
スレッド実行中の適当なタイミングでコンテキストスイッチを行うことは危険です.例えばメモリアロケーション中やリソースのロック保持中,I/O中にコンテキストスイッチが走ってこれらの操作が中断されるとリソースの状態に不整合が発生する可能性があります.
この問題を回避するため,今回の実装ではスケジューラー側がスレッド中の,コンテキストスイッチを行なって問題ないポイントを認識して,そのポイント以外ではコンテキストスイッチを行わない協調的なチェックポイント方式を採用します.
このようなチェックポイント方式自体はGo言語ランタイム組み込みのグリーンスレッド実装であるgoroutine等でも採用されていますが,これらではスレッド側で明示的にチェックポイントを宣言する必要がなく,ランタイムが自動的にチェックポイントを挿入します.さらに言うと,goroutine自体はGo 1.0-1.1では関数呼び出し時のスタックサイズチェック時にチェックポイントがランタイムによって挿入されるようになっていましたが,Go 1.2-1.13では関数プロローグでのスタックチェック時にプリエンプション要求をチェックするようになりました.しかしながらこれらの実装は例えば関数呼び出しを行わない無限ループを持つスレッドに対して脆弱ということもあり,Go 1.14以降ではランタイムがほぼ任意のポイントでチェックポイントを挿入できるようになったようです.この進化についてはこのリンクが詳しいです.
しかしながら今回は実装の簡潔さのためにスレッド側で明示的にチェックポイントを宣言する方式を採用します.協調的なチェックポイント方式では,スレッド切り替えを行って問題ない状況であることをスレッド側が明示的にスケジューラー側に示します.具体的には次のように動作します:
- タイマー割り込みの発生: タイマースレッドが定期的に
SIGALRMシグナルを送信 - シグナルハンドラーの実行: シグナルハンドラーが
PREEMPTION_REQUESTEDフラグを立てる - チェックポイントでの確認: スレッドが
check_preemption()を呼び出す - フラグの確認:
PREEMPTION_REQUESTEDがtrueならschedule()を呼び出してコンテキストスイッチ
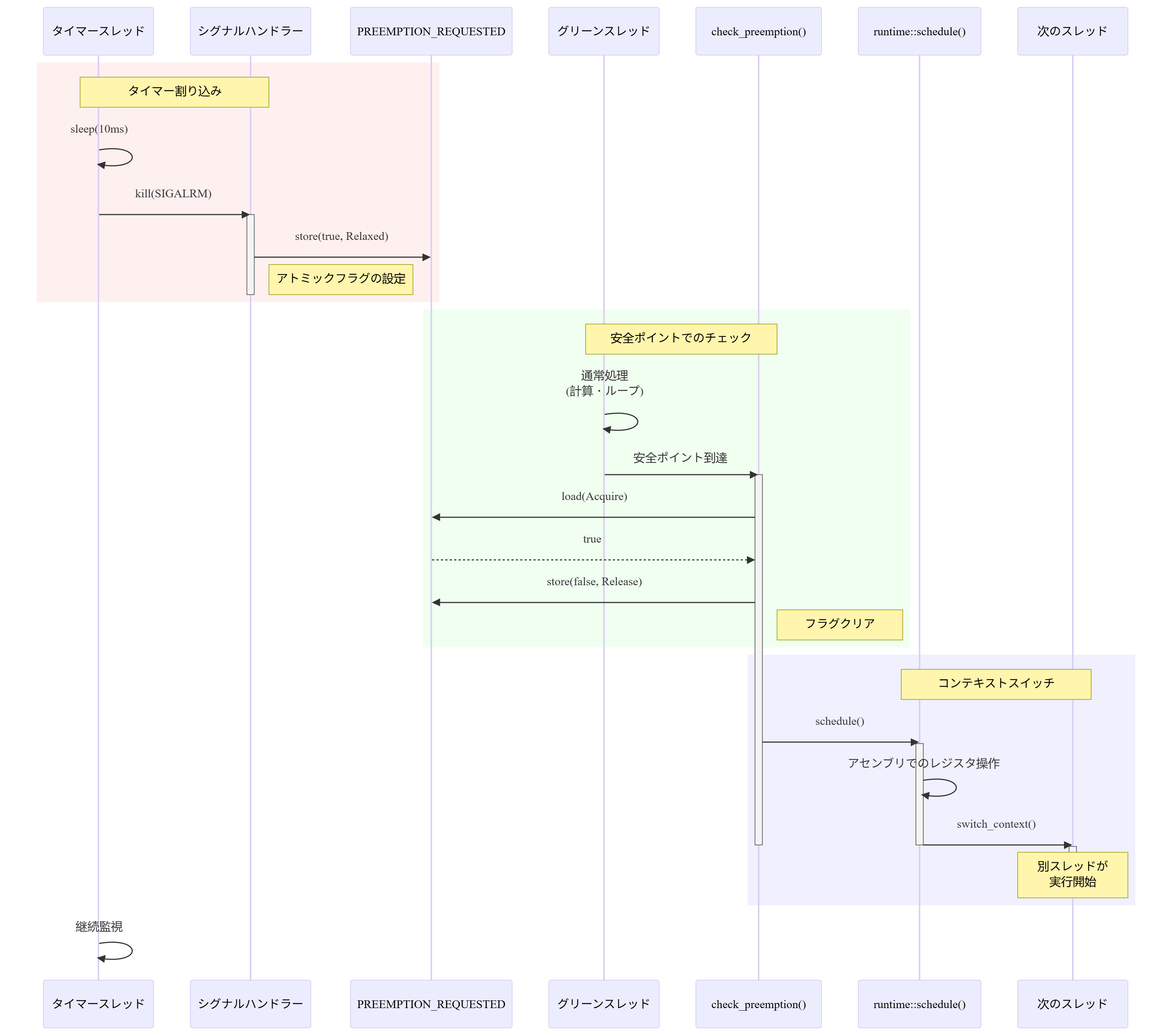
チェックポイントを考慮したコンテキストスイッチのフロー
この機構を実装するためにアトミックに操作が行えるフラグをグローバルに持っておきます:
pub static PREEMPTION_REQUESTED: std::sync::atomic::AtomicBool =
std::sync::atomic::AtomicBool::new(false);
このフラグは複数のスレッドから同時にアクセスされる可能性を考慮して,AtomicBoolを使用してスレッドセーフな操作を保証します.
次にチェックポイントに到達したことをスケジューラー側に伝えるための関数check_preemption()を作成します:
pub fn check_preemption() {
if !is_preemption_enabled() {
return;
}
if crate::types::PREEMPTION_REQUESTED.load(std::sync::atomic::Ordering::Acquire) {
crate::types::PREEMPTION_REQUESTED.store(false, std::sync::atomic::Ordering::Release);
crate::runtime::schedule();
}
}
ここでメモリオーダリングについて補足します.loadにAcquire,storeにReleaseを使用しているのは,フラグの読み書きと他のメモリ操作の順序を保証するためです:
Acquireオーダリング: このload以降のメモリ操作が,このloadより前に並び替えられないことを保証します.これにより,フラグがtrueであることを確認した後のschedule()呼び出しが,フラグ確認より前に実行されることを防ぎますReleaseオーダリング: このstore以前のメモリ操作が,このstoreより後に並び替えられないことを保証します.これにより,フラグをfalseに設定する前に必要な処理が完了していることを保証します
一方,シグナルハンドラー内ではRelaxedオーダリングを使用しています.これはシグナルハンドラーが非同期に実行され,他の複雑な同期は不要で単純にフラグを立てるだけで十分だからです.
この方式により,コンテキストスイッチは常に安全なタイミング(チェックポイント)でのみ発生するので先に述べた問題を回避できます.
ここまでで協調的,preemptiveスケジューラーの両方を実装したので,実際にこれらを使ってスレッドスケジューリングが機能しているかどうかを見てみます.
まず協調的スケジューラーを試してみます:
let coop_scheduler = lachesis::CooperativeScheduler::new();
for i in 0..3 {
if let Err(e) = coop_scheduler.add_task(Box::new(move || {
for j in 0..3 {
std::hint::black_box(i * j);
println!("Task {}: Executing inner loop {}", i, j);
}
})) {
eprintln!("Failed to add task: {}", e);
if !e.is_recoverable() {
return;
}
}
}
coop_scheduler.run().unwrap();
このコードを実行すると次のような出力が得られます:
Task 0: Executing inner loop 0
Task 0: Executing inner loop 1
Task 0: Executing inner loop 2
Task 1: Executing inner loop 0
Task 1: Executing inner loop 1
Task 1: Executing inner loop 2
Task 2: Executing inner loop 0
Task 2: Executing inner loop 1
Task 2: Executing inner loop 2
これはキューの先頭から順にスレッドがFIFOで実行されていることを示していて,協調的スケジューラーが動作していることが分かります.次にpreemptiveスケジューラーの動作を確認してみます:
fn main() {
let scheduler = lachesis::Lachesis::builder()
.stack_size(4 * 1024 * 1024)
.preemption_interval(10)
.build();
scheduler.run(main_green_thread).unwrap();
}
fn main_green_thread() {
// 関数ポインター
lachesis::spawn(worker_thread_1, 2 * 1024 * 1024);
lachesis::spawn(worker_thread_2, 2 * 1024 * 1024);
// クロージャー
let thread_name = "Closure Worker 1";
let iteration_count = 8;
let work_amount = 900000;
lachesis::spawn(move || {
println!("{} starting", thread_name);
for i in 0..iteration_count {
println!("{}: {}", thread_name, i);
for j in 0..work_amount {
std::hint::black_box(i * j);
}
lachesis::check_preemption();
}
println!("{} finished", thread_name);
}, 2 * 1024 * 1024);
// メインスレッドも作業を行う
for i in 0..5 {
println!("Main Thread: {}", i);
for j in 0..600000 {
std::hint::black_box(i * j);
if j % 60000 == 0 {
lachesis::check_preemption();
}
}
}
}
この例では,関数ポインターとクロージャーの両方を同じスケジューラーで実行しています.各ワーカー内で定期的にcheck_preemption()を呼び出すことで,チェックポイントを設けています.実行すると手元では次のような出力が得られました(実行順序は保証されないため毎回異なります):
出力例
Worker thread 1 starting
Worker 1: 0
Worker 1: 1
Worker 1: 2
Worker thread 2 starting
Worker 2: 0
Worker 2: 1
Worker 1: 3
Worker 2: 2
Worker 2: 3
Worker 2: 4
Closure Worker starting
Closure Worker: 0
Closure Worker: 1
Main Thread: 0
Main Thread: 1
Main Thread: 2
Worker 1: 4
Worker 1: 5
Worker 1: 6
Worker 2: 5
Worker 2: 6
Closure Worker: 2
Closure Worker: 3
Closure Worker: 4
Main Thread: 3
Main Thread: 4
Worker 1: 7
Worker 1: 8
Worker 1: 9
Worker 2: 7
Worker 2: 8
Closure Worker: 5
Closure Worker: 6
Worker 2: 9
Closure Worker: 7
Closure Worker finished
各ワーカーが交互に実行されている様子を見ることができ,preemptiveなスケジューラーの動作も確認できました.
本記事では,協調的,preemptive双方のスケジューリングを行えるスレッドスケジューラーを実装しました.高級プログラミング言語(Rust)からアセンブリによる低レイヤー操作まで広く触れることができ,システムコール,シグナル,割り込み,スタック,メモリオーダリング等の周辺知識にも触れることができました.
特にpreemptiveスケジューラーについては相当の拡張の余地があると思います.例えば次のような事項です:
- スレッド間通信とメッセージパッシング: 現在の実装では独立したタスクの並行実行に焦点を当てていますが,スレッド同士が協調して動作するためのメッセージパッシング機構を実装することができます
- スレッドごとに優先度を設定する: 他のスレッドよりも優先的に処理して欲しいスレッドを作成したい需要も考えられます.実際リアルタイムOSなどの文脈ではこうした優先順位を設定できる仕組みが設けられている場合があります
- スレッドのチェックポイントをランタイムで自動的に設定できるようにする: goroutineのように,ランタイム側で
check_preemption()相当の処理を行うようにしてやるとスレッド側で明示的にチェックポイントを設ける必要が無くなります.例えばforループのラッパーを作成して各ループの最後にチェックポイントを設けるようなマクロを用いると比較的簡単に実現できるでしょう - マルチスレッド対応: 現在の実装ではシングルスレッドで動作するスケジューラーとなっていますが,これをマルチスレッドで動作できるようにするとより効率的です.実際これを見据えた実装を記事中ではいくつか行っています
本記事の内容がシステムプログラミングに興味を持つきっかけとなり,より様々な技術に触れる一助となれば幸いです.